NocabSoftware.com
Genetic ATTAck on Classifiers Agents (GATTACA)
TL;DR:
I trained a genetic algorithm to corrupt an image in an attempt to confuse ResNet. The digital organism was allowed to apply some gray-scale filters to the original image, but had to keep some percentage of the original image, 10-60%.
I chose this corruption option because I wanted to find a diverse family of creative solutions that could ‘trick’ the model. I knew that simply adding noise until the image was mostly static was effective, but I wanted to find less invasive techniques that kept the majority of the image relatively untouched. While genetic algorithms are slow and not guaranteed to produce optimal results, they can produce a diverse family of reasonable results.
The genetic algorithm applied several random gray filters to the image (gradients, noise, mandelbrot set). The set of filters that were most effective at confusing ResNet (measured as a decrease in the logits compared to that of the unmodified image) were mutated and/or merged with the other most fit list of filters. This was done for 10 generations. At first, the filters had to keep 90% of the original image, but this restriction was relaxed for the next 10-generation training, until 60% of the original image was allowed to be discarded.
While the 60% blend-ratio organism learned the strategy of “cover everything”, the 30% blend-ratio organism was somewhat more strategic, cutting the image down the center and creating distracting regions of light and dark. Overall, the ResNet classifier was difficult to defeat, but it seems that at about 50% blend ratio (meaning discarding 50% of the image) the strategy of quantity over quality is more effective at confusing the classifier.
Very few of the most fit organisms used the Gaussian Noise filter, demonstrating that ResNet is somewhat resilient to such corruption, and instead sharp regions of light and dark corruption are more effective at confusing the classifier.
A more sophisticated genetic algorithm with more training time may be able to produce better results, however this proof of concept shows that a diversity of strategies may be effective at attacking classifier agents.
Further Reading
Deep learning models are effective at classifying data, especially tasks such as labeling images. ResNet is a notable example here, representing near state of the art in accuracy, and near human performance. However, these models are not perfect, and falter when presented corrupted images. The exact process by which a complex model like ResNet considers an image and produces a label is not perfectly understood, so the techniques for tricking these models are also not entirely understood. Today, I’m taking a black-box approach to attacking these models, and have built a genetic algorithm to learn to corrupt a small set of 10 images to maximally confuse the classification model.
The Genetic Algorithm:
I am representing a pipeline of image transformations as an ‘Organism’, which contains an ordered string of transformations. These transformations are called the ‘DNA’ of the Organism, which is made of 6 Chromosomes. For this proof of concept, I’ve implemented 5 different transformation/ Chromosomes:
- Empty (No change to the image)
- Noise (Gaussian applied evenly to the image)
- Linear Gradient (A linear gradient of black to white applied at a random angle to the image)
- Radial Gradient (A gradient of black to white originating from the center of the image outwards)
- Mandelbrot (A certain zoom and level of detail of the Mandelbrot set)
Each of these transformations, called Chromosomes in the code, is blended with the original image at a certain ratio (discussed later).
After the Organism’s transformation is applied to the image, both the original and corrupted image are passed through the classifier. The difference between the two logits values is the fitness of the Organism; A series of transformations that causes the classifier to drop in confidence is considered fit, while organisms that cause little change in the classifier’s black box behavior is considered unfit.
The 8 most fit organisms are then randomly mutated, and the DNA between them are merged to generate the next generation of transformation organisms. This process was repeated for 10 generations.
Why Genetic Algorithm:
I chose to build a genetic algorithm because I wanted to see a diversity of corruption techniques. Genetic algorithms are slow, not guaranteed to be optimal, or even good. But they often can produce a family of passable solutions for a problem. I wasn’t sure what corruption technique would be most effective, and when it comes to combining techniques the scale of possibilities is overwhelming. But a genetic algorithm can happily chug and produce somewhat fit combinations of corruptions. Although, in this particular case the best strategy seems to be simply stacking different crops of the Mandelbrot Set, but which crops and zooms is not obvious and the genetic algorithm does generate somewhat unique options here.
The genetic algorithm is also easy to scale in complexity, simply implementing more transformation Chromosomes. I only focused on adding black/ white gradients to the image, but color, blur, rotation, crop, etc. are all possible transformations that can be added in.
Corruption:
Comparing the most fit organism after 10 generations of training yields disappointing results:
On the left is the unmodified image, and the right is the fittest organism:


The organism applied 4 radial gradients, and 1 noise transformation, reducing the models confidence by a measly 0.3906 logits values. This strategy should be an extremely effective one: Adding more shade to the center of the image where the main object is likely to be, does seem like a good strategy.
However, for this first run I have purposely kept the blend ratio low, at less than 10%. Meaning that, when applying the transformation, the organism must keep 90% of the original image during the blending process.
I ran subsequent tests, where this blend ratio was increased by increments of 10 up to 60% (meaning the organism was allowed to discard 40% of the original image at the end).
Here are the results of the best organism after 10 generations for each blending regime.





In the 20% and 30% blend images, the mandelbrot set dominates, the edges of the overlapping regions creating distracting lines that split the middle of the picture and create regions of dark and white. While the 50% and 60% blend organisms are clearly going for quantity over quality, simply flooding the image with gradients, they try to block as much as possible.
Analysis
If we compare the fitness of the best organism over the 10 generations for each of the blend regimes, we can clearly see that more generations tend to produce better results. Allowing the organism to drop more of the original image also improves corruption performance.
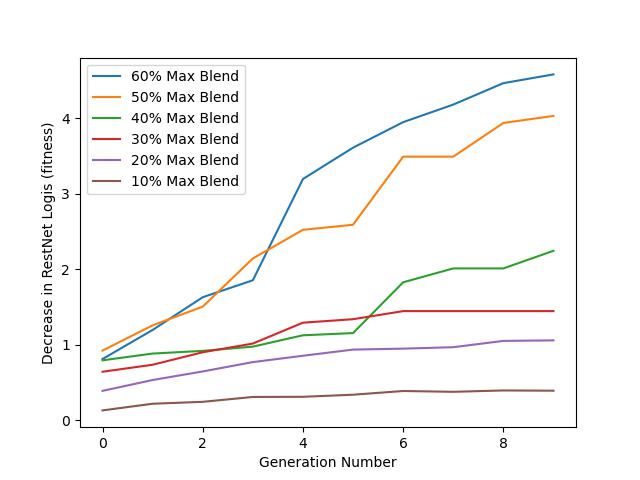
But there seems to be a major jump in performance between the 40% and 50% regime. I believe this is because the strategy of “blocking” becomes more effective than “tricking” the classifier network. If we compare the 40% and 50% blend ratio images above, the 40% still clearly has a sharp line through the middle of the image, while the 50% has more alignment between the two filters causing a larger percentage of the image to be darker.
Conclusion:
There seems to be two main strategies developed by the genetic algorithm for defeating the ResNet classifier: Block out as much of the image as possible, or try to trick the classifier by making dark lines and slashing through the center of the image. From this, I can conclude that the ResNet classification model uses the center of the image more than the edges, and that applying gray filters over an image can confuse it, albeit not by much. This may be due to the training of the classifier model, perhaps the original developers included noise to their training data, or in the model itself via dropout. The fact that the simple “noise” filter was rarely used in any of the fittest organisms also supports the conclusion that sharp changes of gradient are more effective at confusing the ResNet model.
Additionally, I believe that a genetic algorithm could be effective at confusing an image classification model. Deep learning models are often vulnerable to out-of-distribution attacks, where the data fed into them is wildly different from the data used to train the classifier. Genetic algorithms are largely capable of producing a diverse family of ‘creative’ solutions to a given problem. Including problems like defeating a ResNet classifier. While the results of this proof of concept are not revolutionary, they are not null. Further work including adding more complex transformations to the digital organism’s arsenal, longer training times with larger generational pools, and a more sophisticated fitness function are all worth pursuing in the effort to find vulnerabilities in a ResNet image classifier.