NocabSoftware.com
Chat With Maps: How well do AI Chat Models Reason with Map Images?
AI chat models have recently added the ability to consider and respond to image data in addition to the traditional text data. The ability to “chat with images” has made these models multimodal. As humans, we often use images to communicate with each other, from the simple emoji to the complex college professors white board, images can offer another way to communicate ideas. So in theory, the addition of images to a chatbot’s arsenal of understanding will help make them more effective at their job of ‘chatting’.
And while this may be true for simple chats, more rich discussions involving more complex ideas require more complex pictures. An example of a complex concept that can best be represented is maps. A map is an informationally dense piece of media, requiring skills like spatial reasoning, search, imagination, planning etc. to use properly.
I have also found in my personal use of these models that they are not very good at creating maps. I am a dungeon master for a group of friends, playing Dungeons and Dragons. Together, we explore fantasy settings with heroes and monsters. While there are several AI image generation tools that excel at helping me create character portraits, backdrops and magic items, I have yet to find a tool that can produce good maps so instead I use the old fashioned technique: Hand drawn.
For example, here are some results for the prompt “A map of the london metro, pixel art style” with the Bing Image creation tool, which itself is powered by Dall-E:
Putting aside the generation model’s issues with creating text, the structure of the maps themselves are weird. Some of them have train lines clearly running into the sky, lines that have no stops, lines that change colors, and generally this is functionally unusable as a map.
Here is another example without the “pixel art style” in the prompt, next to the real map of the London Underground.
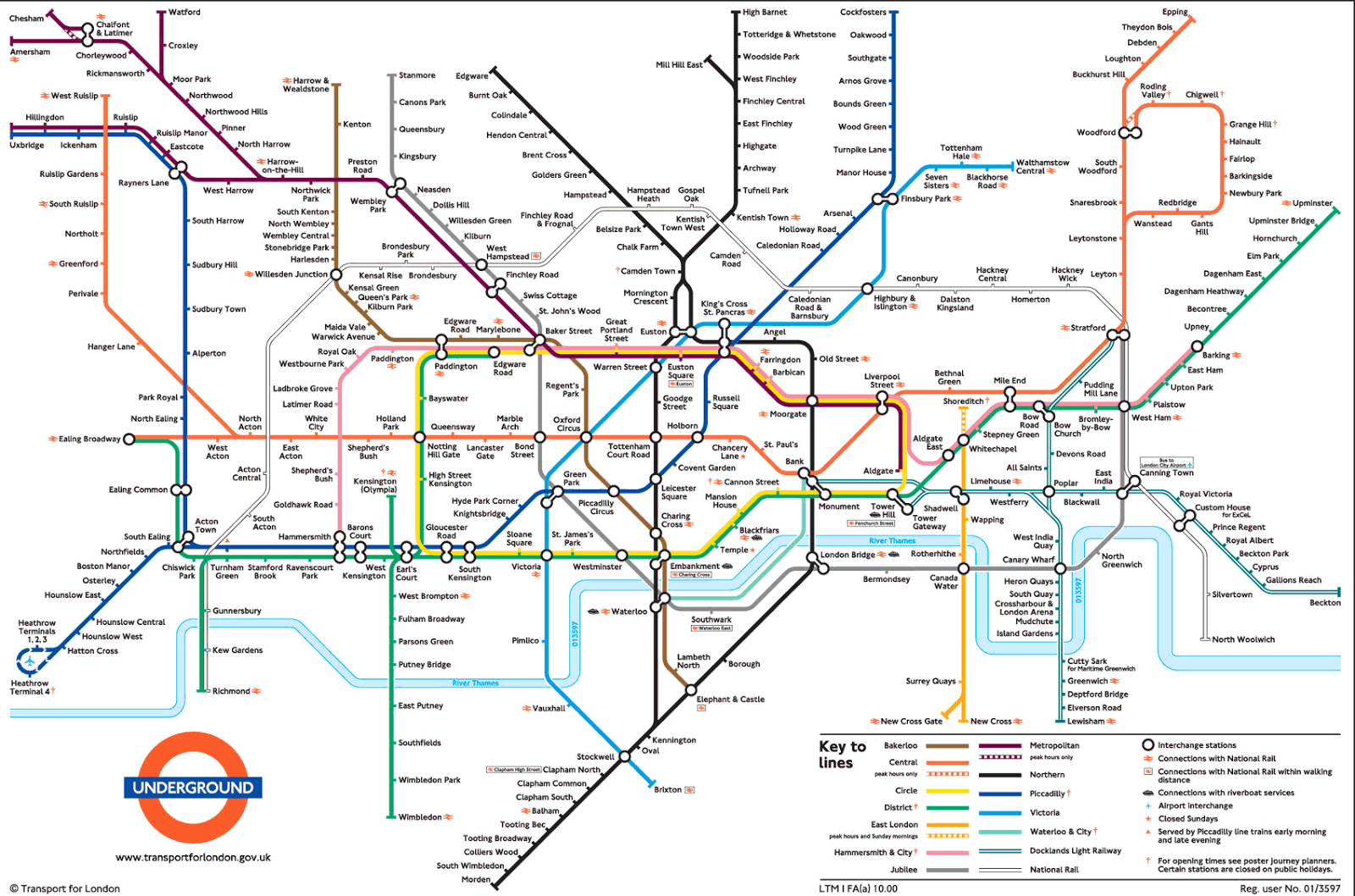
Notice how the AI generated image captures the structure of a real map, but none of the meaning. These AI generated maps are functionally useless.
However, generating maps is quite a difficult task. Perhaps simply reading and understanding maps will be somewhat easier?
I asked the Gemini chat model by Google to consider a map, describe it, and generate paths between two points.
First was a map of the Washington DC Metro system. I asked it what it could tell me about the map.
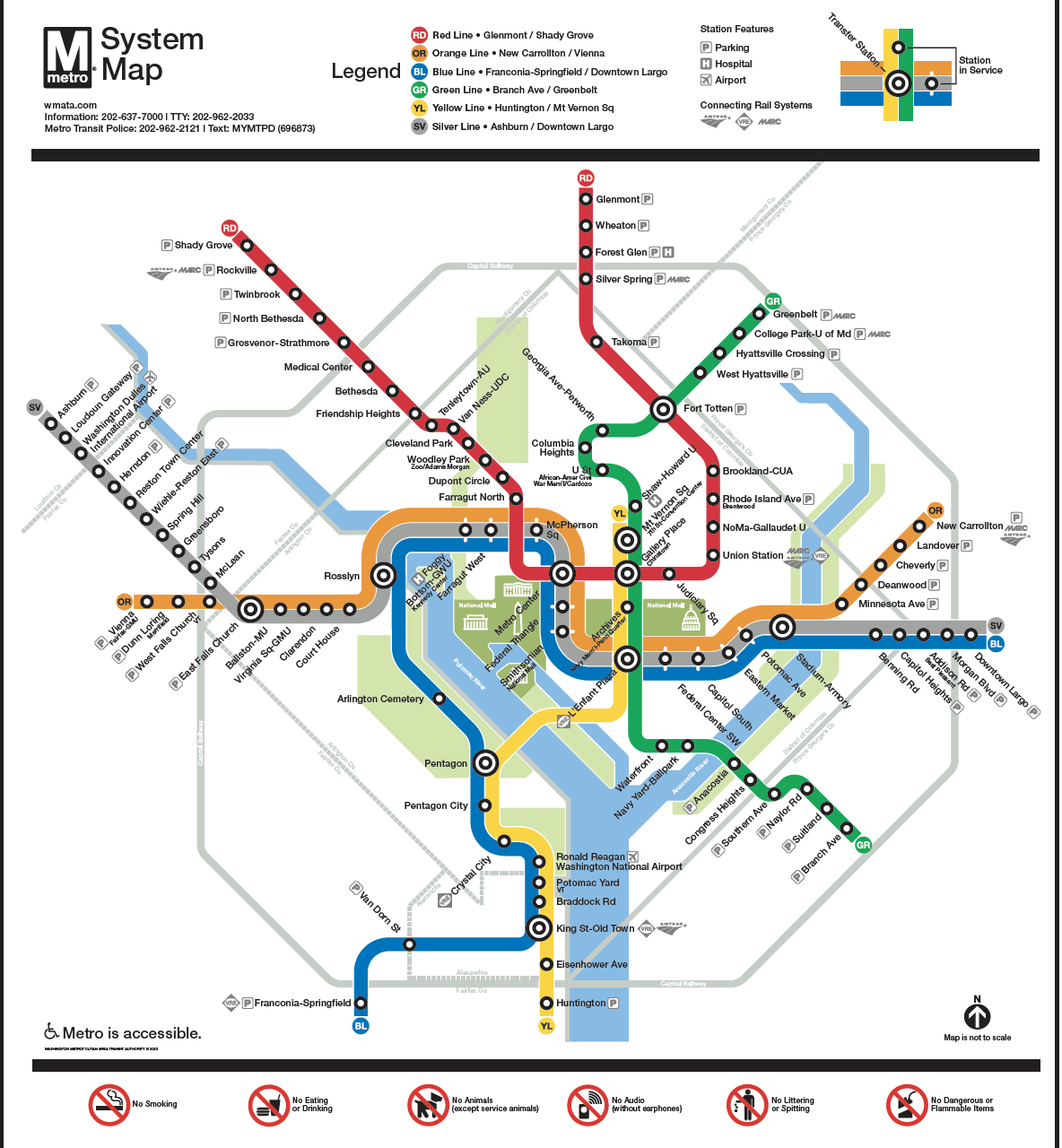
It successfully recognized it as a map of the DC metro system. The filename was randomized, but despite that it successfully named the different Lines, identified the legend, and described key elements of the map.

Next, I asked “Using that map (uploaded again to this msg) how would one get from Pentagon City to Metro Center?”Both Pentagon City and Metro Center are stations. In order to answer this question it needs to be able to read the text in the image, search from the starting station to the destination, track any important events like line transfers, and report it back to me succinctly.
The results were impressive, but incorrect.Captured here are three of the reported draft responses to my query. All three drafts are wrong, oftentimes telling you to go in the wrong direction, or make connections that don’t exist. I’ve highlighted the map showing the path that the chat model wants us to take.

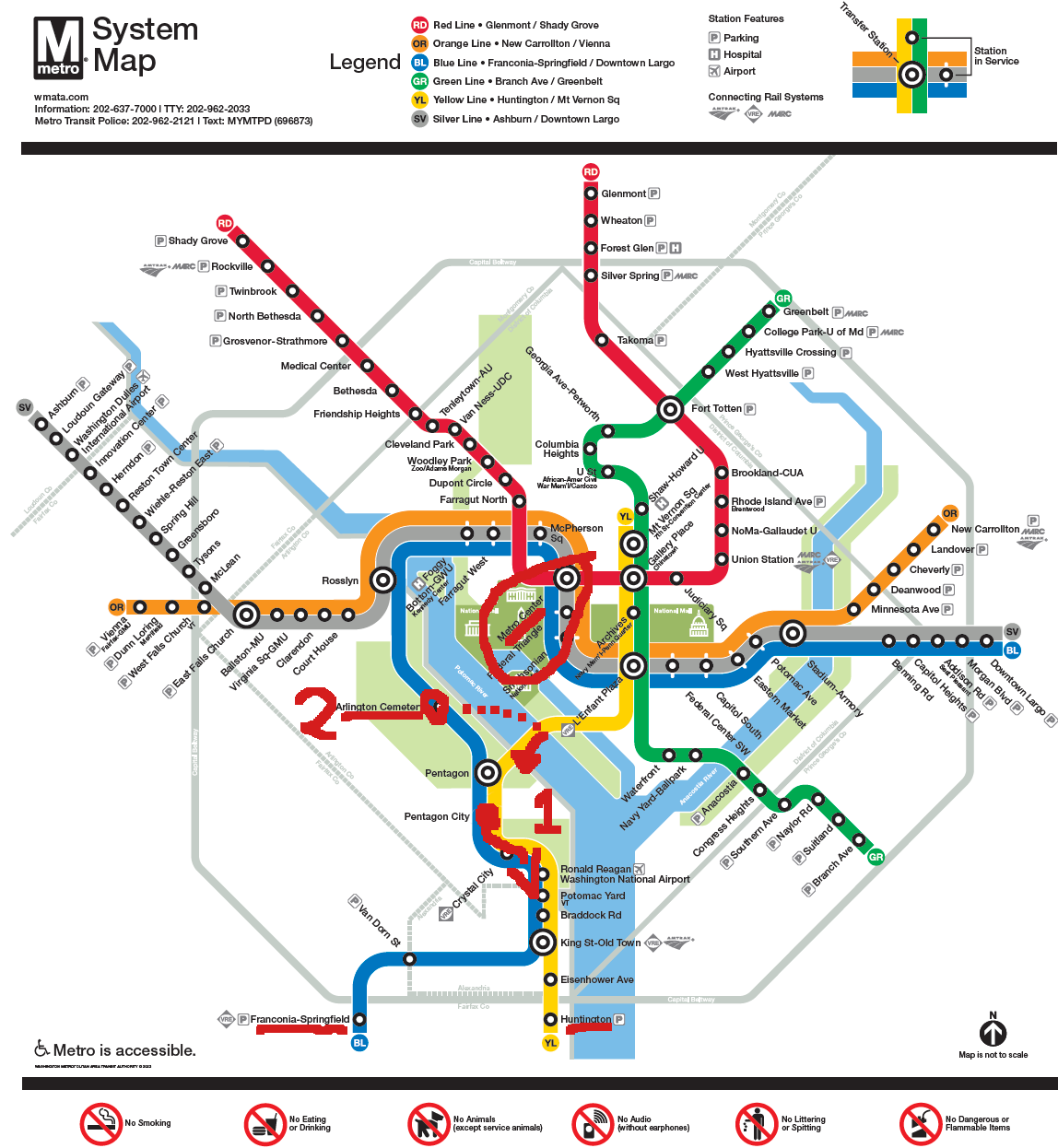
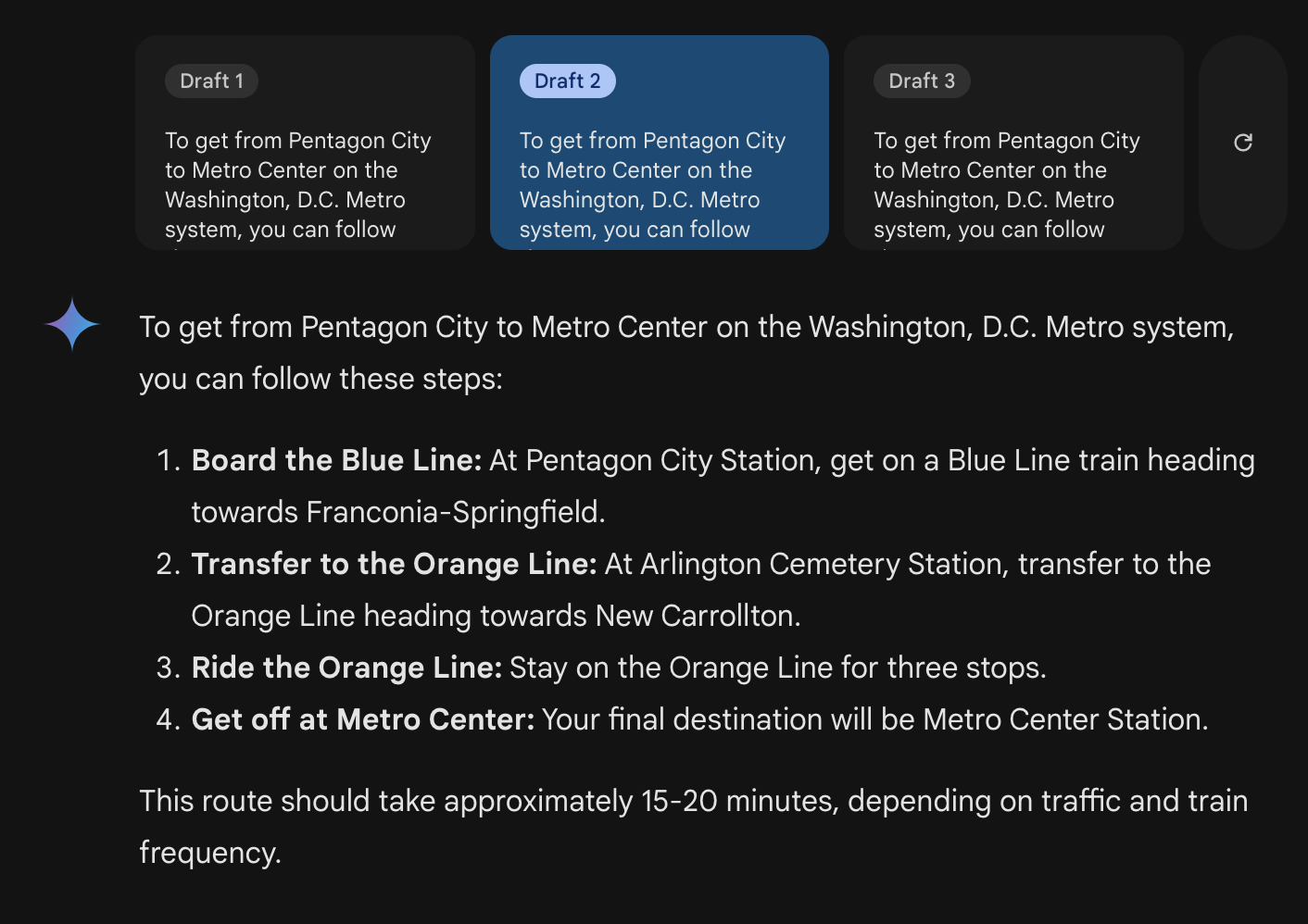
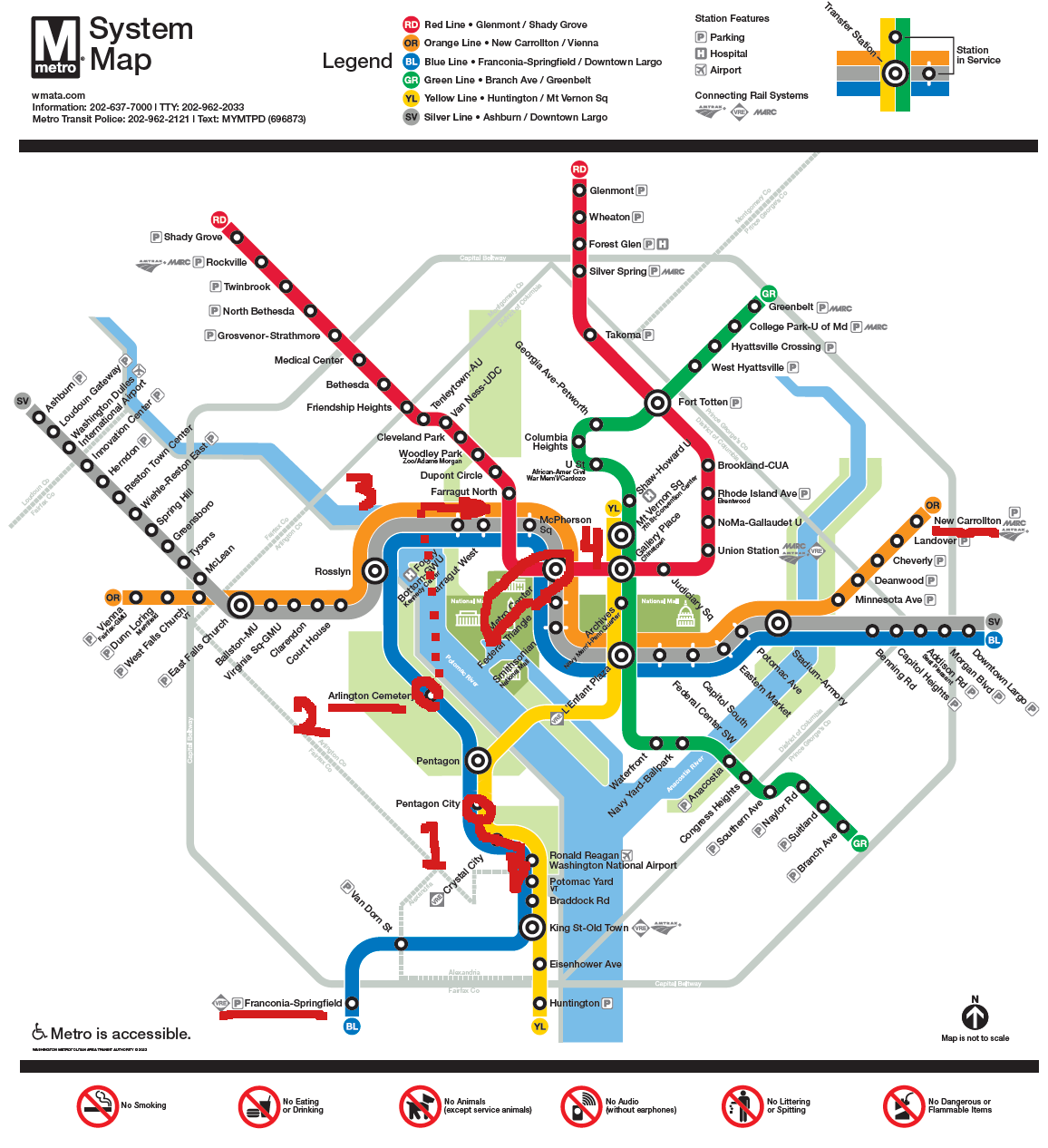
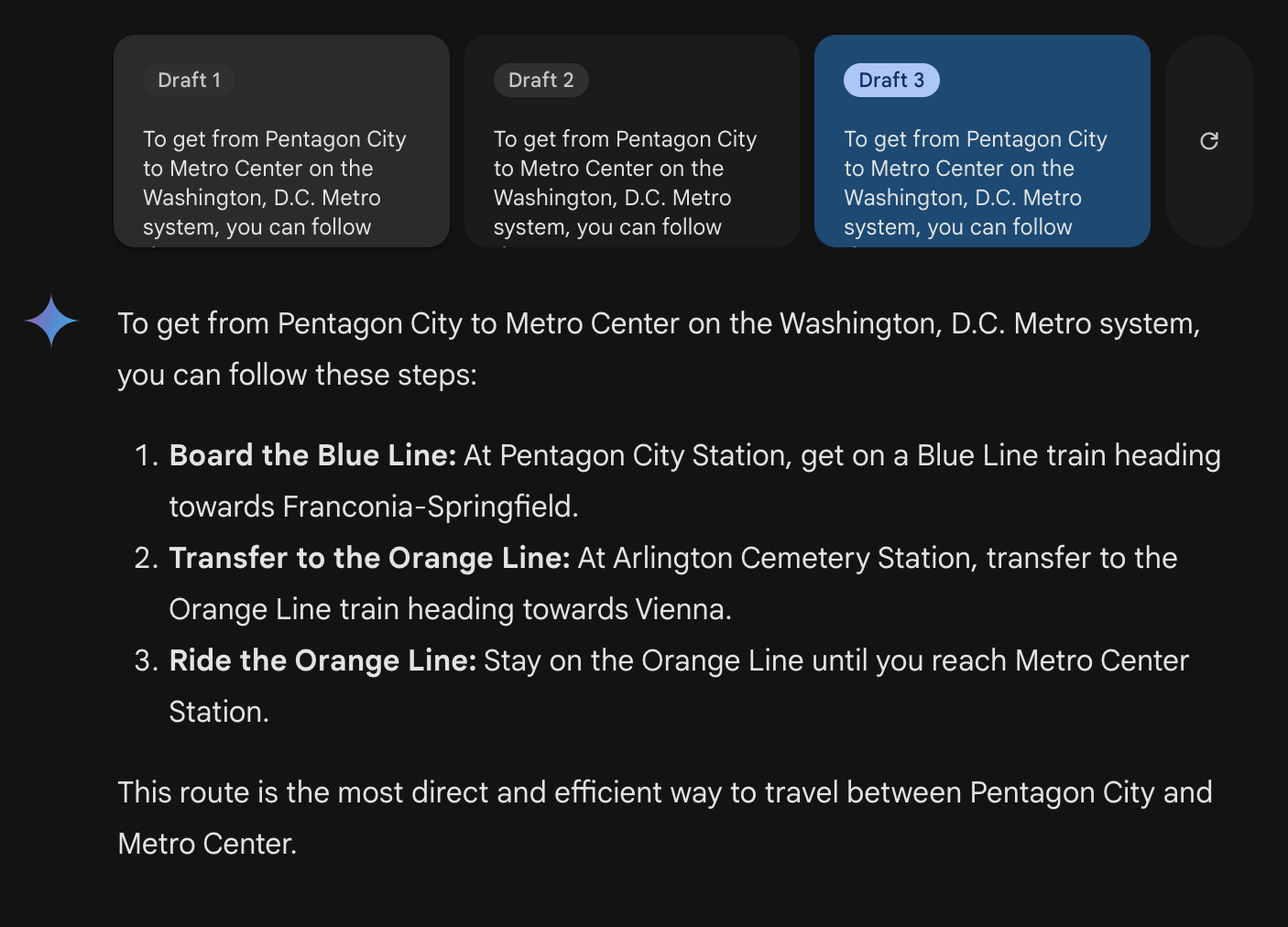
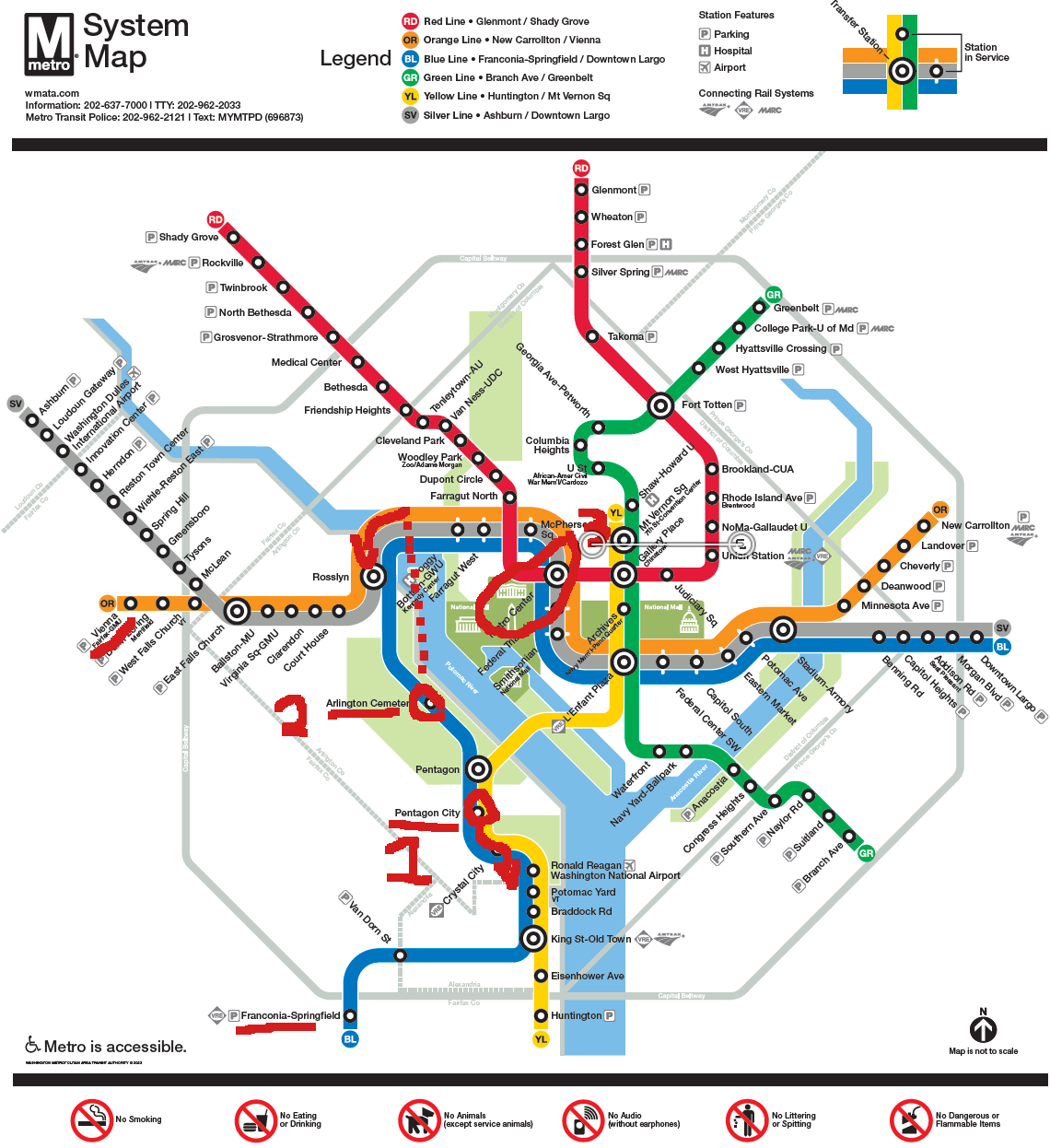
Notably, there are 6 different times the model tells us to board a train in a set direction. 5 of those times are in the wrong direction. So it is worse than randomly guessing. Of course this is a small sample size, but it’s clear that the model is not processing the graph properly.
I do want to point out that it’s possible to get on the blue line at Pentagon City going towards Downtown Largo for 7 stops, and getting off at Metro Center. No transfer needed.
I thought, perhaps the Washington DC metro system is popular so the chat models training data included a lot of directions navigating it? Perhaps it’s not actually processing the image and instead is relying on its text training data?
So I repeated the experiment with a fantasy map. Originally I wanted to use one of my own hand drawn maps that I know has never been on the internet. But the chat model would not accept my drawing simply stating that an error occurred. So I had to settle for some other fantasy map I found online:
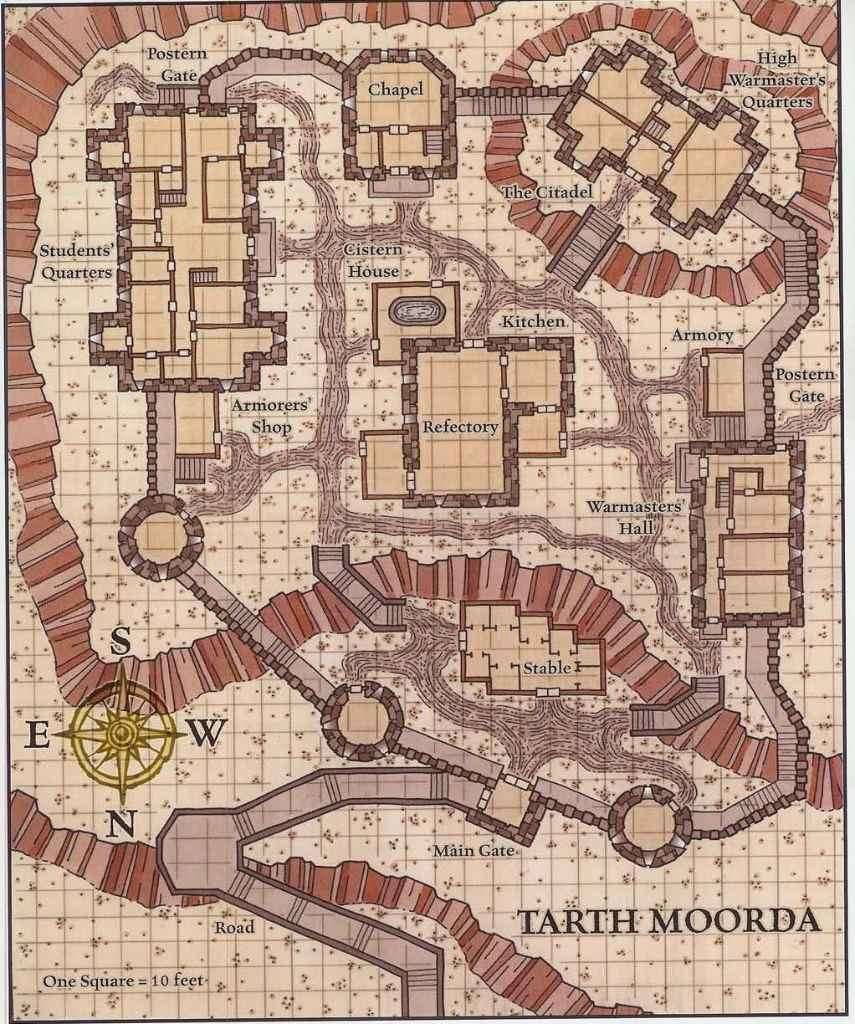
Just as last time, I asked it to “tell me about this image” and it responded correctly that it was a map of a settlement or castle and probably used for a fantasy/ storytelling/ role playing game. It was able to successfully read the text from the image and repeated back a few noted locationsI asked it first to navigate me from the chapel to the Armory and it responded:

While somewhat ambiguous, we can generously map the AI’s path to something like this:
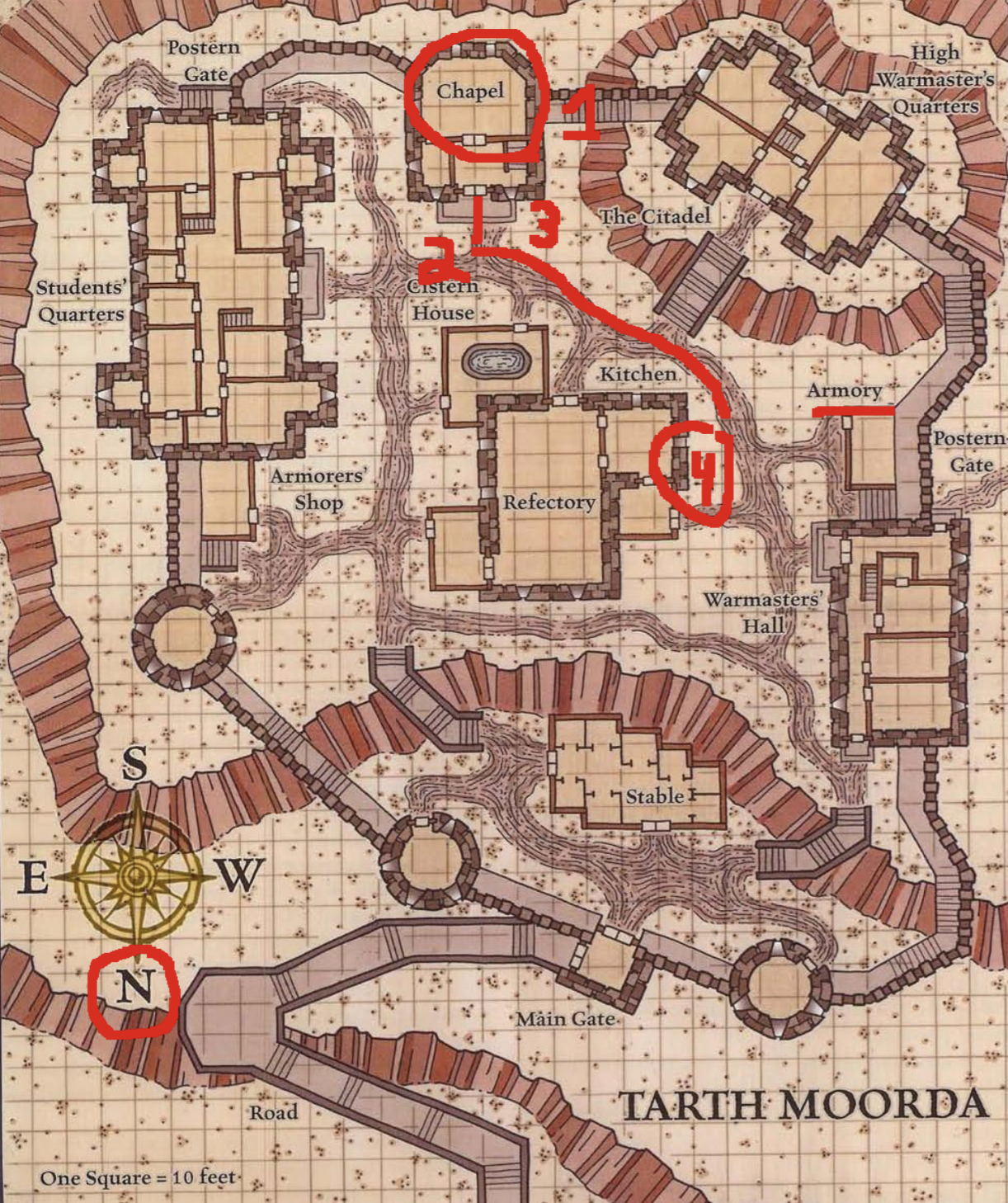
Notice that the compass has North pointing downwards. Overall, the AI did a much better job at understanding this map, and while step 4 is incorrect (the Armory is on the West side of the road) it did a reasonable job.
I asked it again to travel from the Armory to the Armorers’ Shop, and it did not do nearly as well.

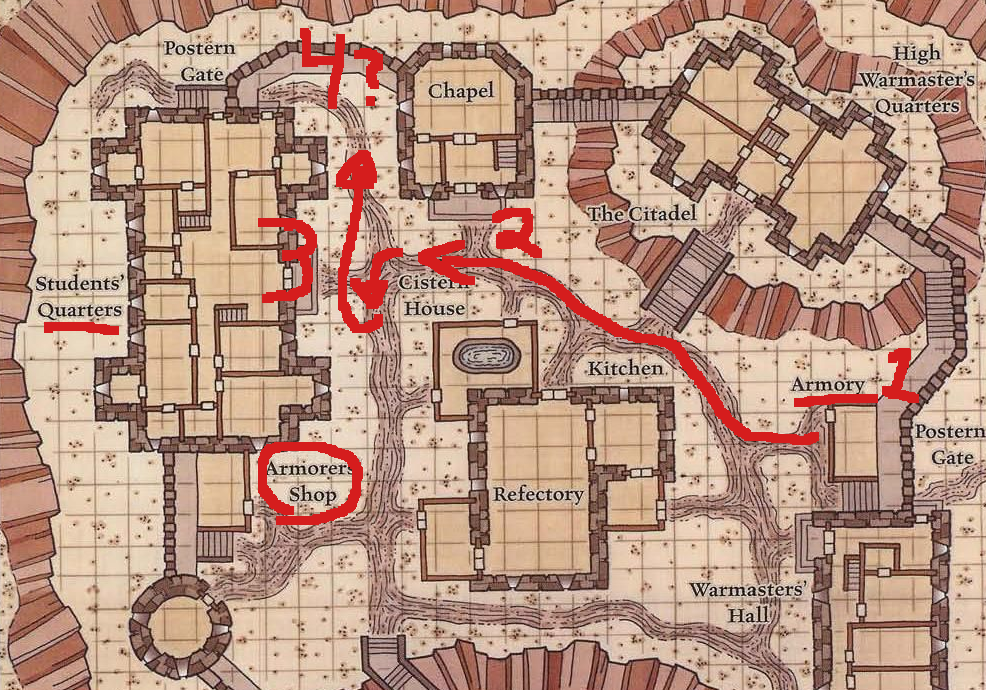
Again, it’s not clear what is the main road in this town. But generously interpreting the AI’s output leads us nearly there. In step 3, we’re instructed to “Turn left on the main road and continue walking south”. However, turning left would cause us to go North (north is towards the bottom of the map).
The AI however, does seem to recognize that the Students’ Quarters are near the Armorers’ Shop, but it ‘thinks’ that we won’t pass the Students’ Quarters on our trip which is not correct.
While these models clearly are considering the maps, they are still prone to hallucination. The results from my quick experiments lead me to believe that the chat models aren’t entirely making up a plan. In the Washing DC Metro example, the model knew what color lines are available at Pentagon City, the starting point. But almost every single instruction it gave was in the wrong direction, and it didn’t have a clear understanding of what stops are available at Metro Center. It seemed overly eager to transfer to different lines, when a simple straight line path was available.
For the fantasy map, it likewise seems reasonable. However, in the two different pathfinding exercises it used the term “main road” to refer to two different roads. And it did get it’s cardinal directions mixed up, telling us to “turn left and walk South”.
While these models are able to easily describe and extract key pieces of information from images, they seem unable to deeply study these images. Perhaps it’s a result of their training data which may focus on things as opposed to maps, which is a picture of a picture. Or perhaps this behavior is an artifact of their multimodal nature; converting the image into its corresponding textual tags and processing only the text under the hood. Whatever the explanation, I do not believe that these chat models are able to build complex ‘mental models’ which humans use to plan, search or imagine themselves walking along a path depicted by a simple flat map.